Windows11 Ollama Deepseek 通义千问 CherryStudio MCP入门笔记 home 编辑时间 2025/04/16  <br><br> ## 前言 <br><br> ## 折腾 <br> **第一步下载安装Ollama** https://ollama.com/download/windows <br> **第二步安装本地模型** 这里ollama官方就有模型库 https://ollama.com/search <br> 包含绝大部分主流模型 比如说选择DeepSeekR1 32B (对应16G显存的显卡) 如图,官方直接给了类似于Docker的安装命令,会自动从ollama官方模型库中下载安装 命令: `ollama run deepseek-r1:32b` 此时把命令丢到powershell里就可以直接一键安装模型了 <br> 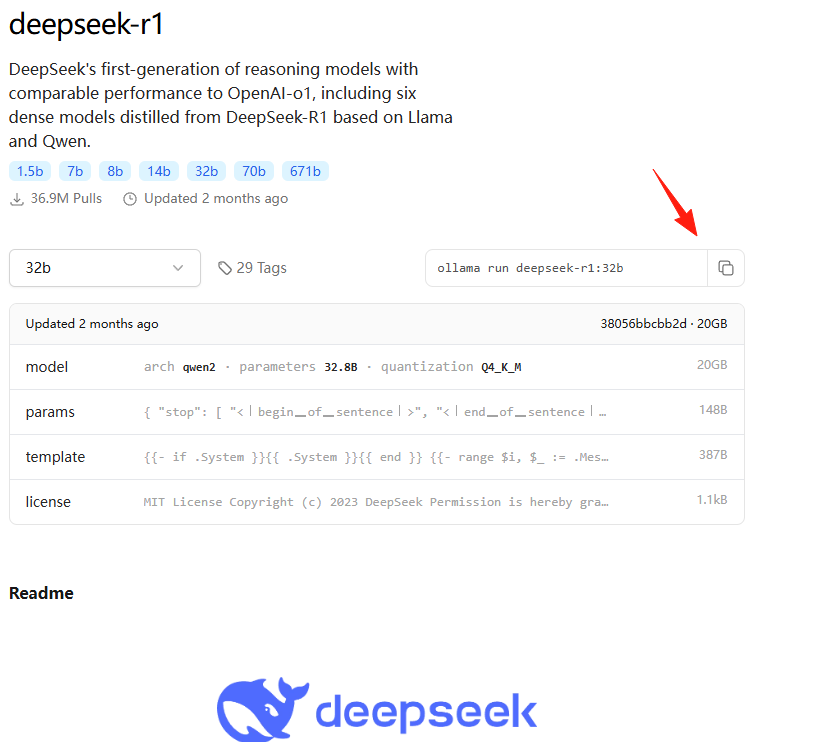 <br> 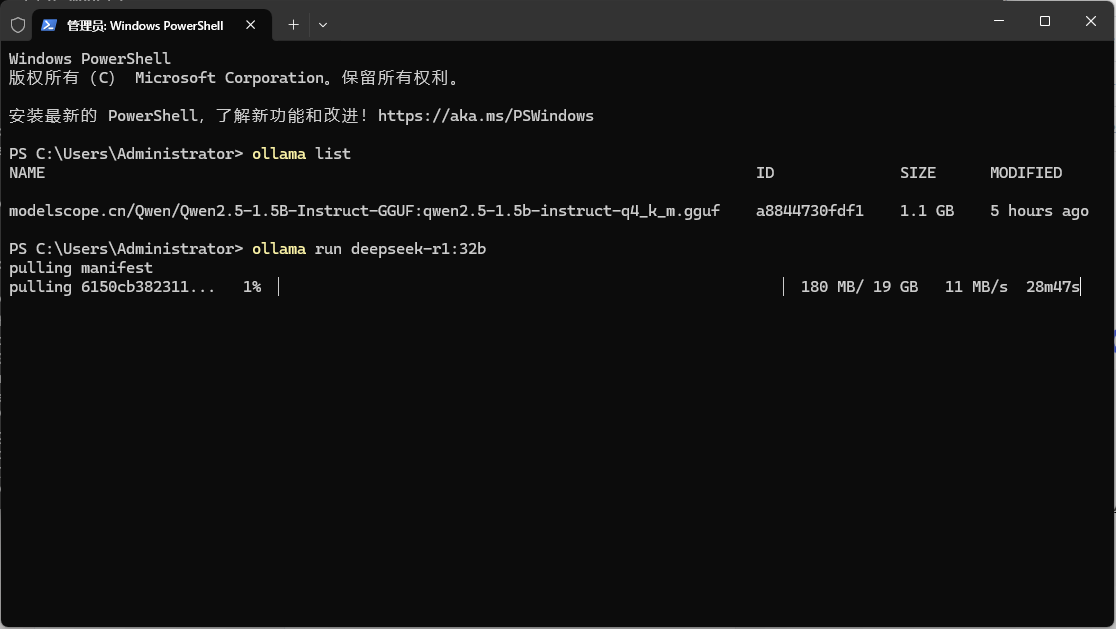 <br> 另外一个方法就是第三方模型库里面可以下载gguf文件 <br> 具体方法就是先去魔塔社区搜模型 https://www.modelscope.cn/models 魔塔自己还有一个ollama加载魔塔模型教程文档 https://www.modelscope.cn/docs/models/advanced-usage/ollama-integration <br> 比如 关键字 `deepseek r1 32b gguf` 这里必须要gguf的格式的模型才可以本地运行 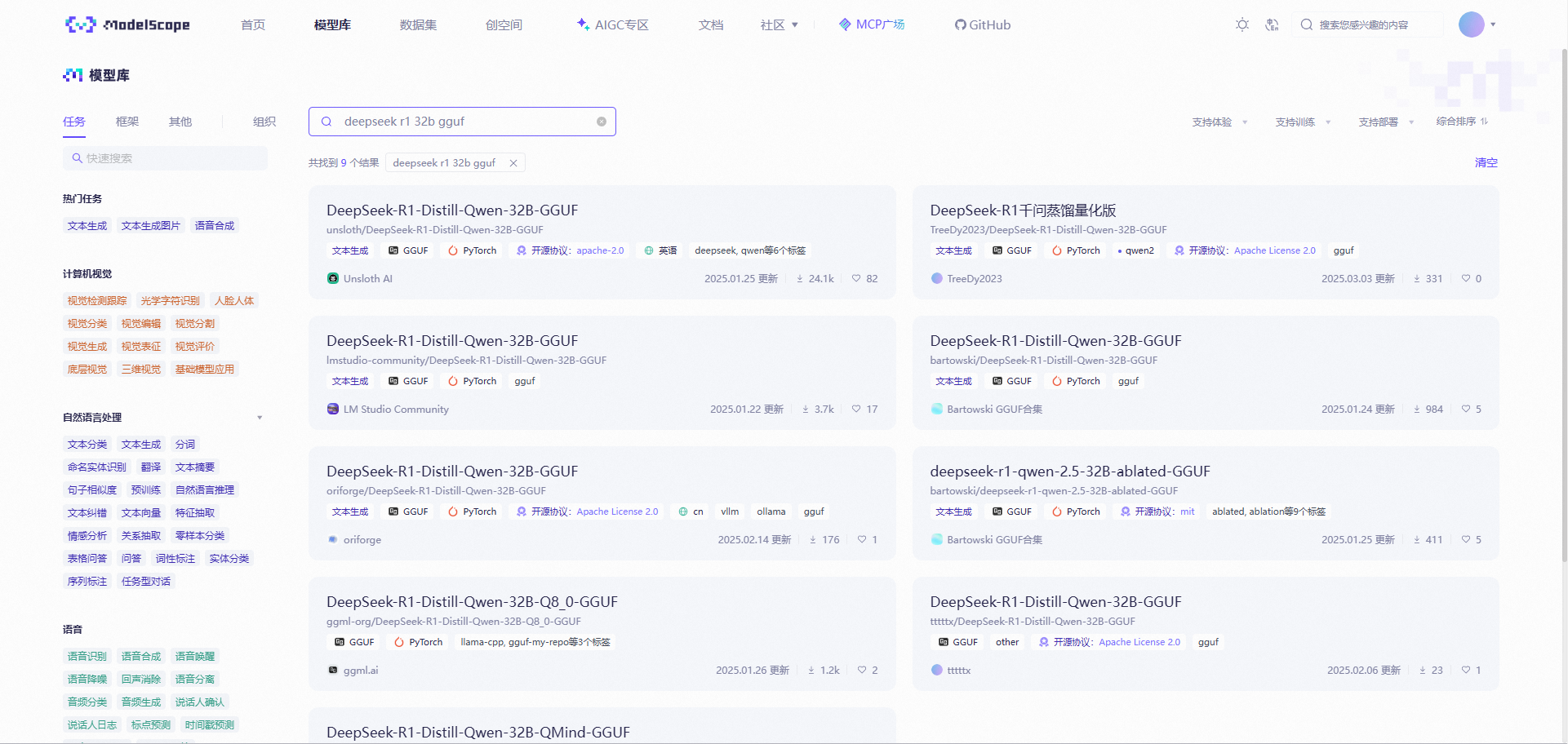 <br> 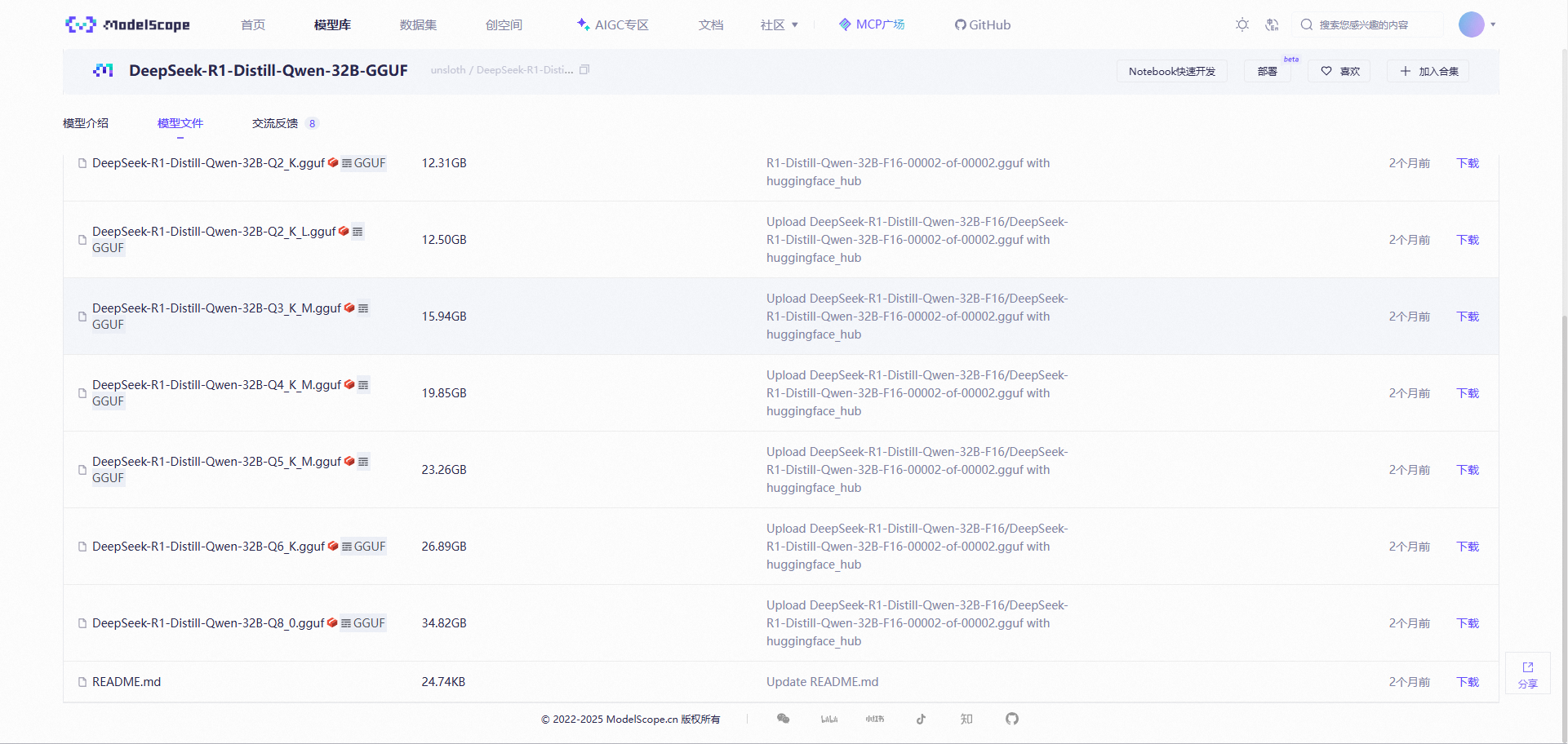 <br> 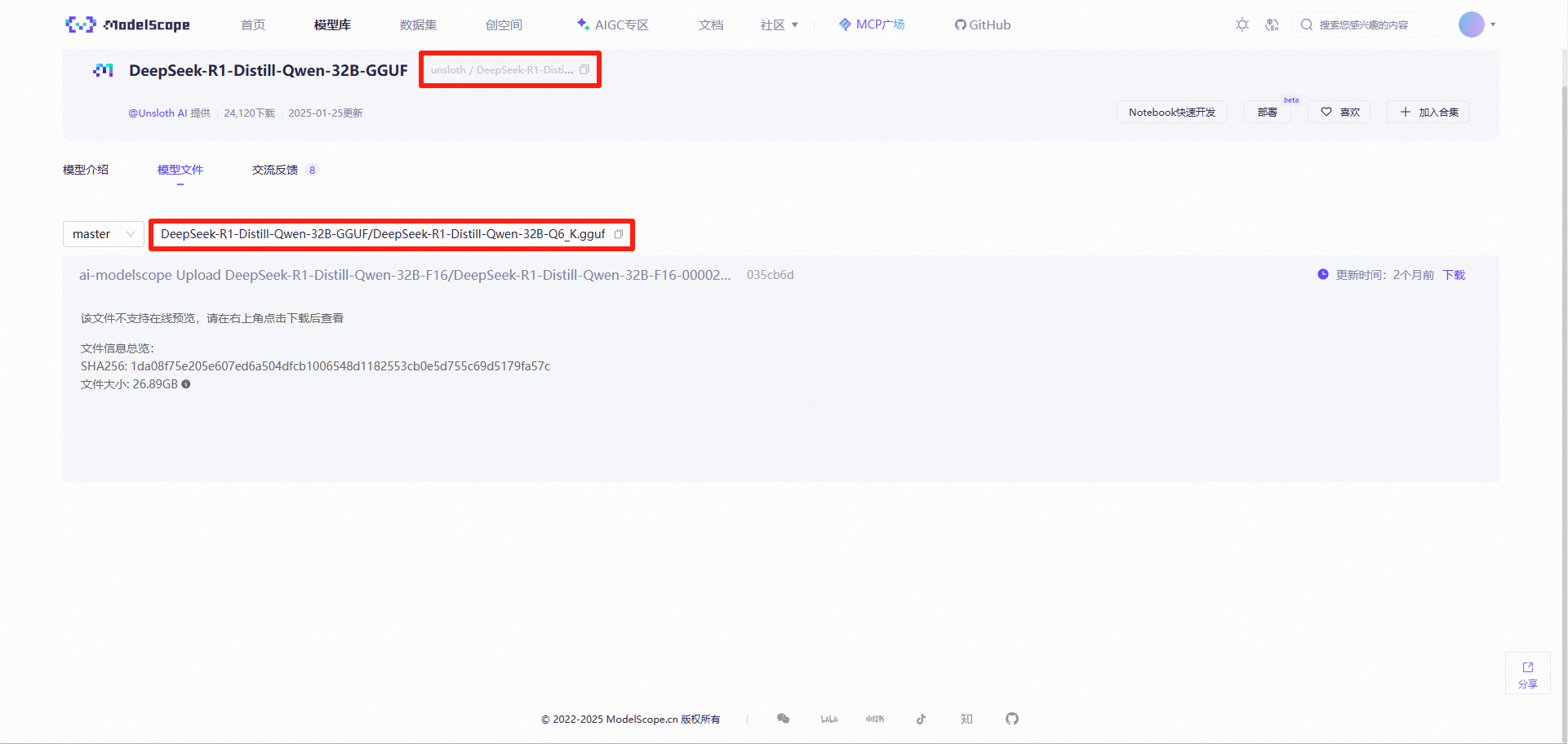 <br> 这里通过 库名+项目名+ 冒号+文件名拼接 得到完整下载地址 `unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF:DeepSeek-R1-Distill-Qwen-32B-Q6_K.gguf` 再在前面加上固定的魔塔专用的链接 `ollama run modelscope.cn/` <br> 完整的就是 `ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF:DeepSeek-R1-Distill-Qwen-32B-Q6_K.gguf` <br> 放在windows的管理员权限的powershell运行就可以了 (win11入口是右击开始菜单,选择 '管理员终端') 如图已开始下载模型 (另外此方式优点是方便,一条命令,不写配置文件,缺点是不支持断点续传,如果中断就要从头开始) 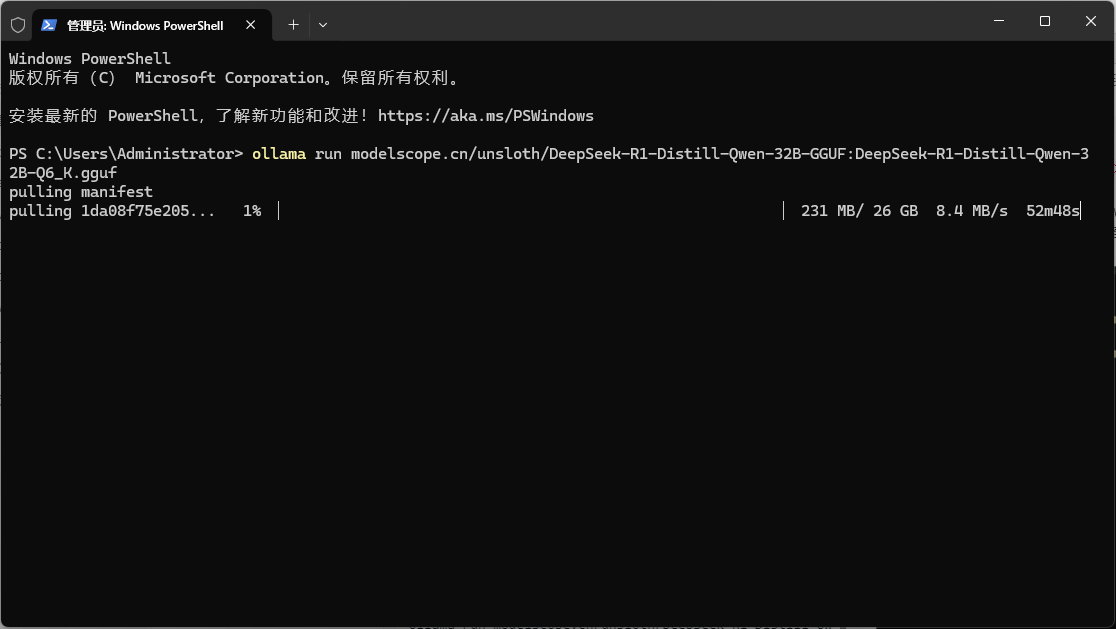 <br> 如果此时此刻,26G的DeepSeekR1 32BQ6K下载太慢,或者显卡跑不太起来。 这里再推荐一个迷你的,显卡1060都能顺畅跑的。擅长中文翻译的。且总大小只有1.1G的。 通义千问2.5-1.5B-Q4 KM https://modelscope.cn/models/Qwen/Qwen2.5-1.5B-Instruct-GGUF/file/view/master?fileName=qwen2.5-1.5b-instruct-q4_k_m.gguf&status=2 <br> 完整命令是 `ollama run modelscope.cn/Qwen/Qwen2.5-1.5B-Instruct-GGUF:qwen2.5-1.5b-instruct-q4_k_m.gguf` <br> 下载完成以后,通义千问会默认被启用,直接可以在powershell中对话 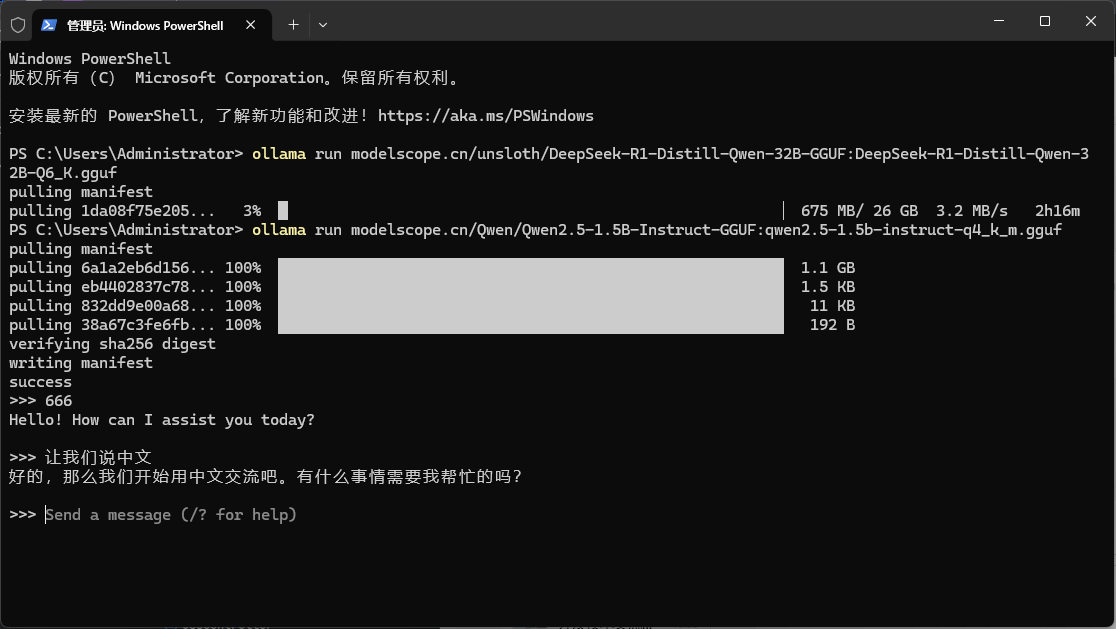 用 `/bye` 命令可以退出对话 <br> 退出对话后,用 'ollama list' 可以看当前有哪些模型 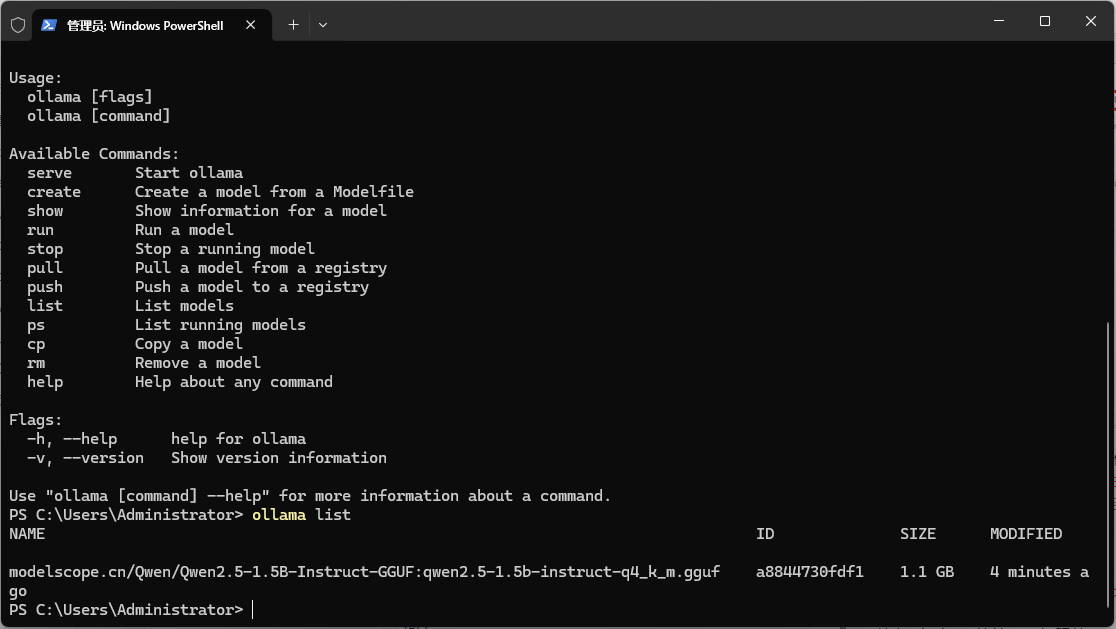 <br> **第三步 安装图形化软件 cherry-studio** cherry-studio 用于图形化界面,补全ollama没有图形化的部分 https://cherry-ai.com/download 首次启动界面是这样的,如果现在对话,会报401,因为没有配置地址和token 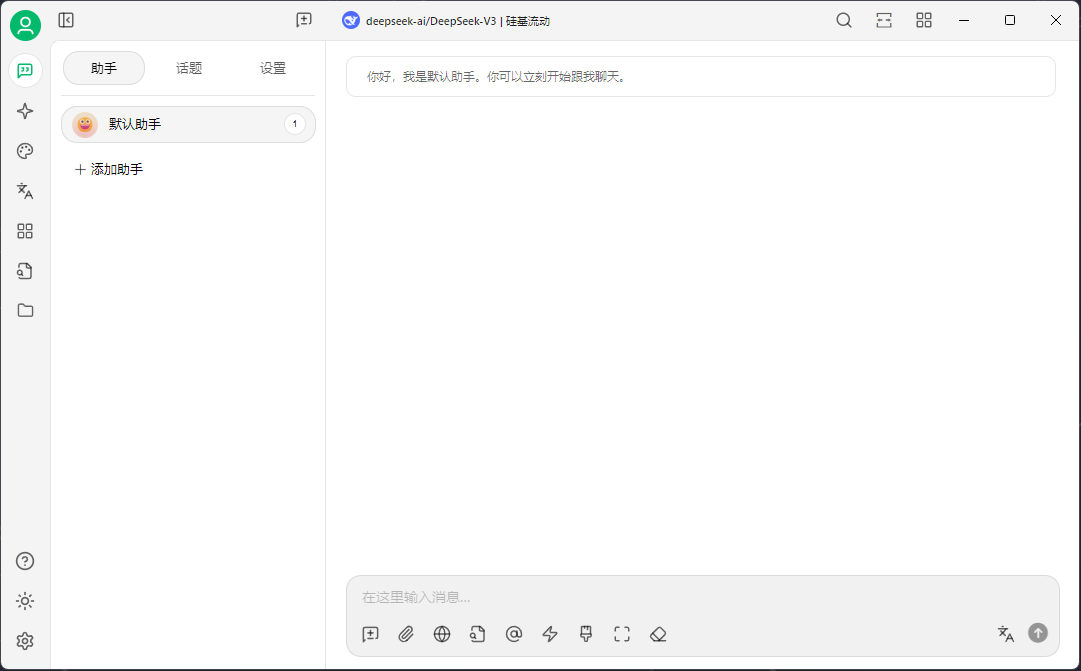 <br> 这里再推荐一个网站 硅基流动 https://cloud.siliconflow.cn/i/2u9olIBn 此网站包含几乎所有主流AI的API和TOKEN 相当于你把钱充值到硅基流动,然后用硅基流动提供的API地址 随便用哪个AI,都扣的硅基流动的余额。首次注册送14元余额。 <br> 所以cherry-studio是有2种用法 1. 是本地部署AI,燃烧显卡,然后充当ollama的图形界面用 2. 是充值线上AI,燃烧人民币,获取API和TOKEN <br> 再补充一下 线上并不一定全都要收费 我这里企图白嫖,点了一下免费模型 发现硅基流动的模型库里,还真有一堆免费模型 而且本地费劲巴拉,只能跑 `千问2.5 1.5b q4 km` 人家免费版直接给你 `千问 7b` 破防了 <br> 本着白嫖即是正义的原则,这里再分叉一下,先讲下如何用cherry studio + 硅基流动,纯线上不烧显卡的前提下,白嫖token <br> 注册 [硅基流动](https://cloud.siliconflow.cn/i/2u9olIBn) 并点击首页 API密钥 获取API密钥 https://cloud.siliconflow.cn/account/ak 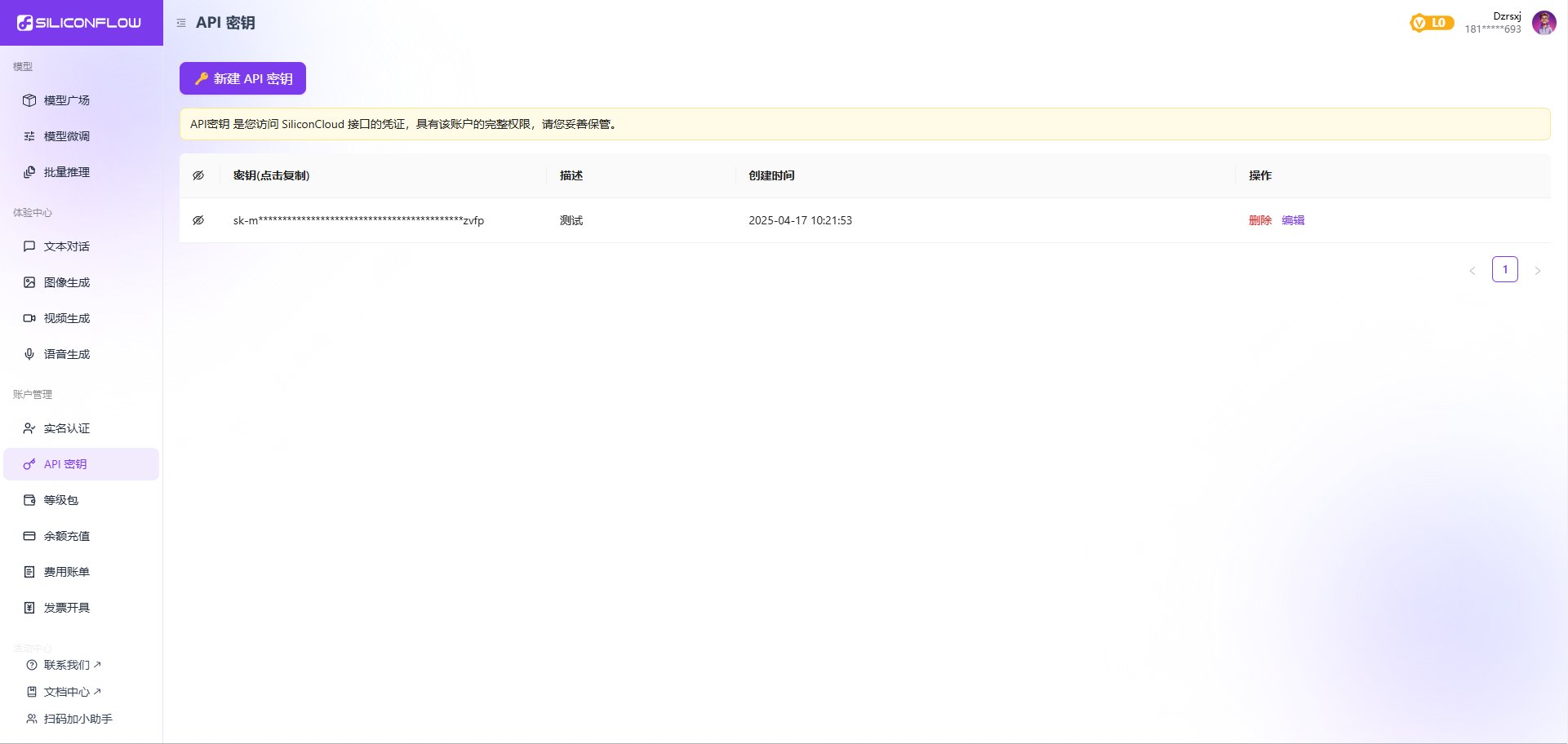 <br> 点击密钥复制 粘贴到cherry studio的设置的模型服务中的硅基流动 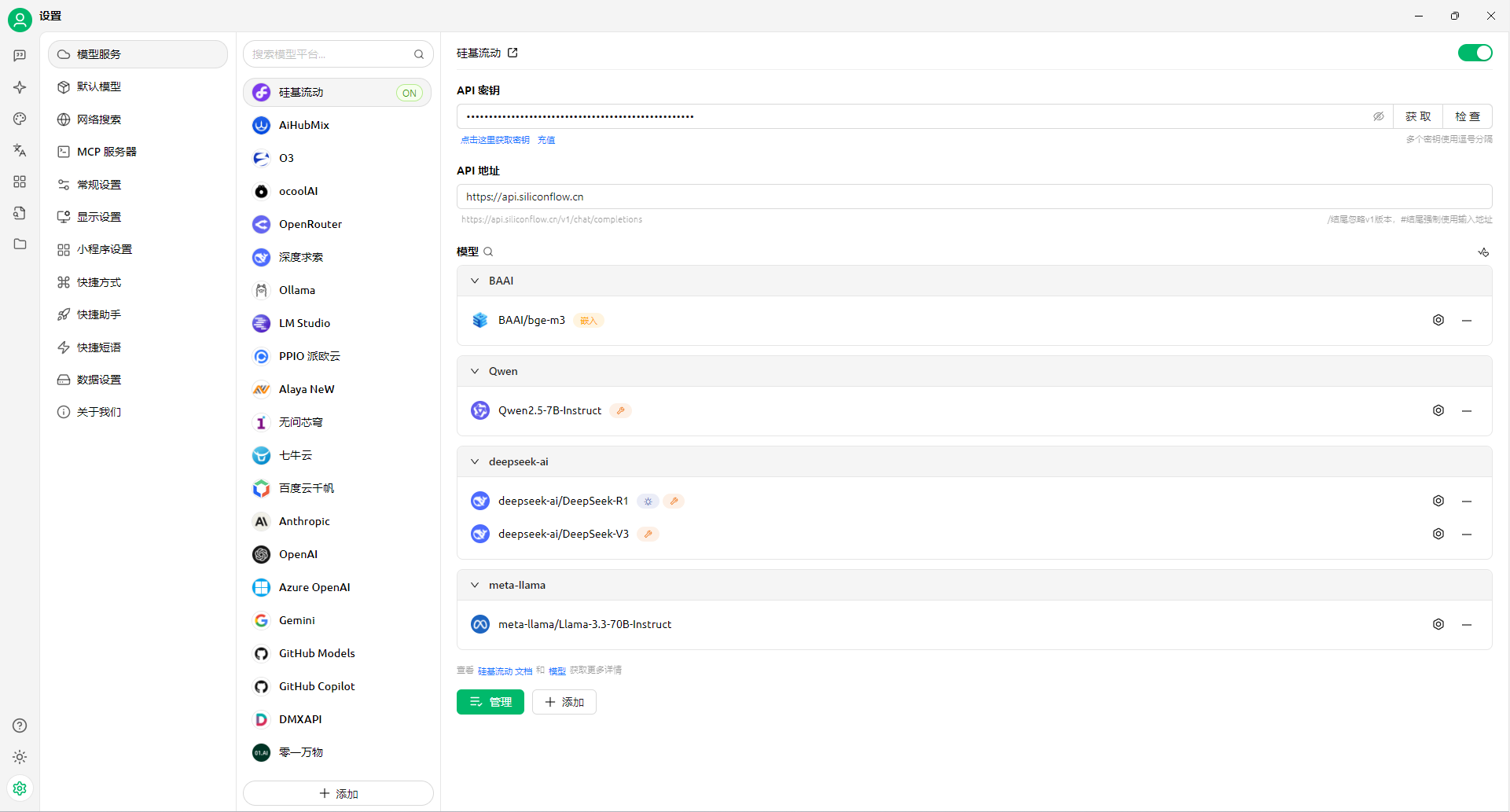 <br> 为了防止用他现有的模型可能会收费 接下来我自己添加几个免费模型进来 <br> 访问硅基流动模型库 https://cloud.siliconflow.cn/models <br> 点 `显示筛选器` 点 `只看免费` 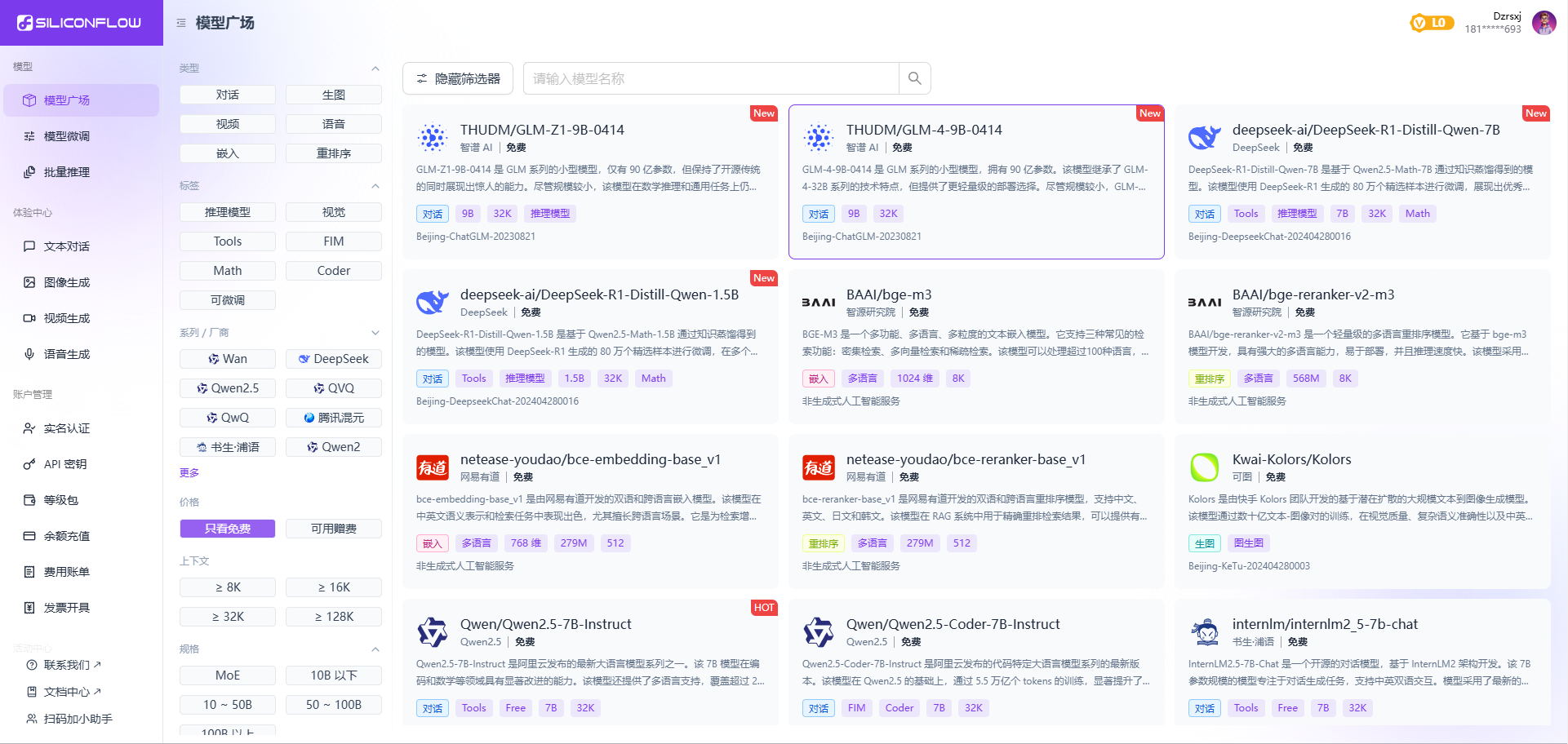 <br> 选择一个模型点击进入详情 我这里选择千问2.5 7b演示 点击右侧模型ID 复制 模型ID 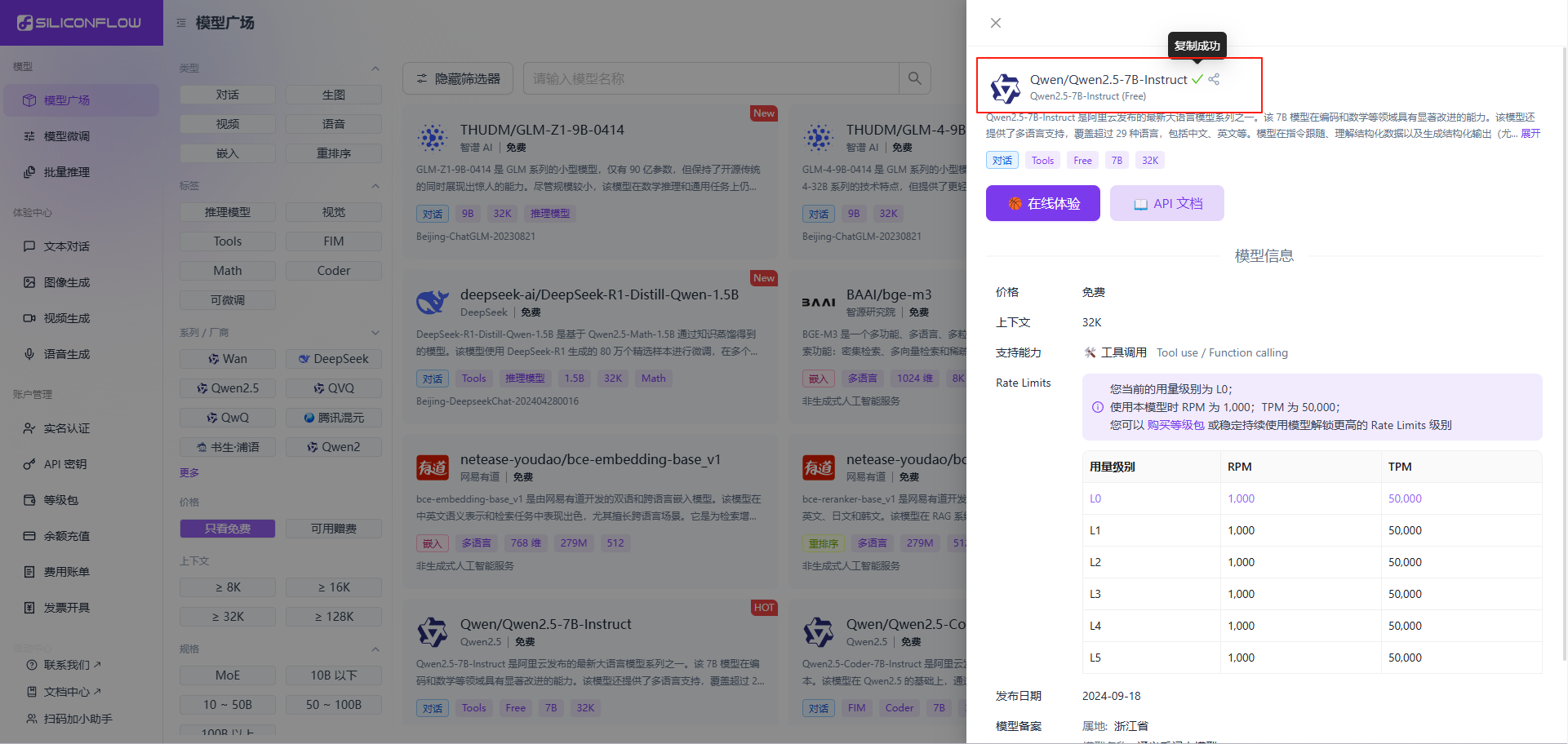 <br> 回到 cherry studio 的设置中的硅基流动界面 点击添加 然后粘贴模型id 点添加模型即可 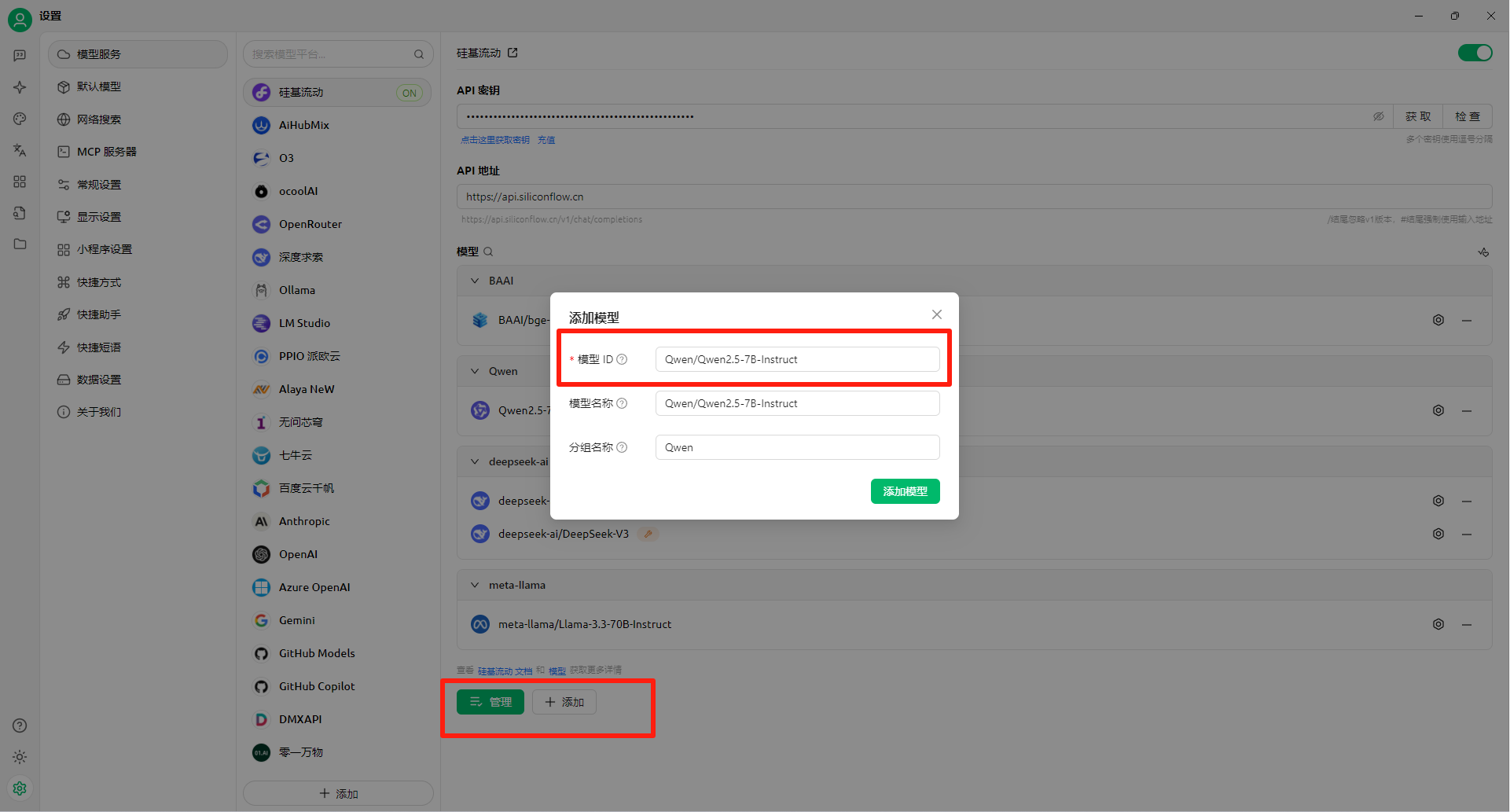 <br> 这里我点添加,出现模型已存在,说明默认自带的这个千问就已经是免费版了 <br> 回到 cherry studio 首页 点击顶部tab切换模型 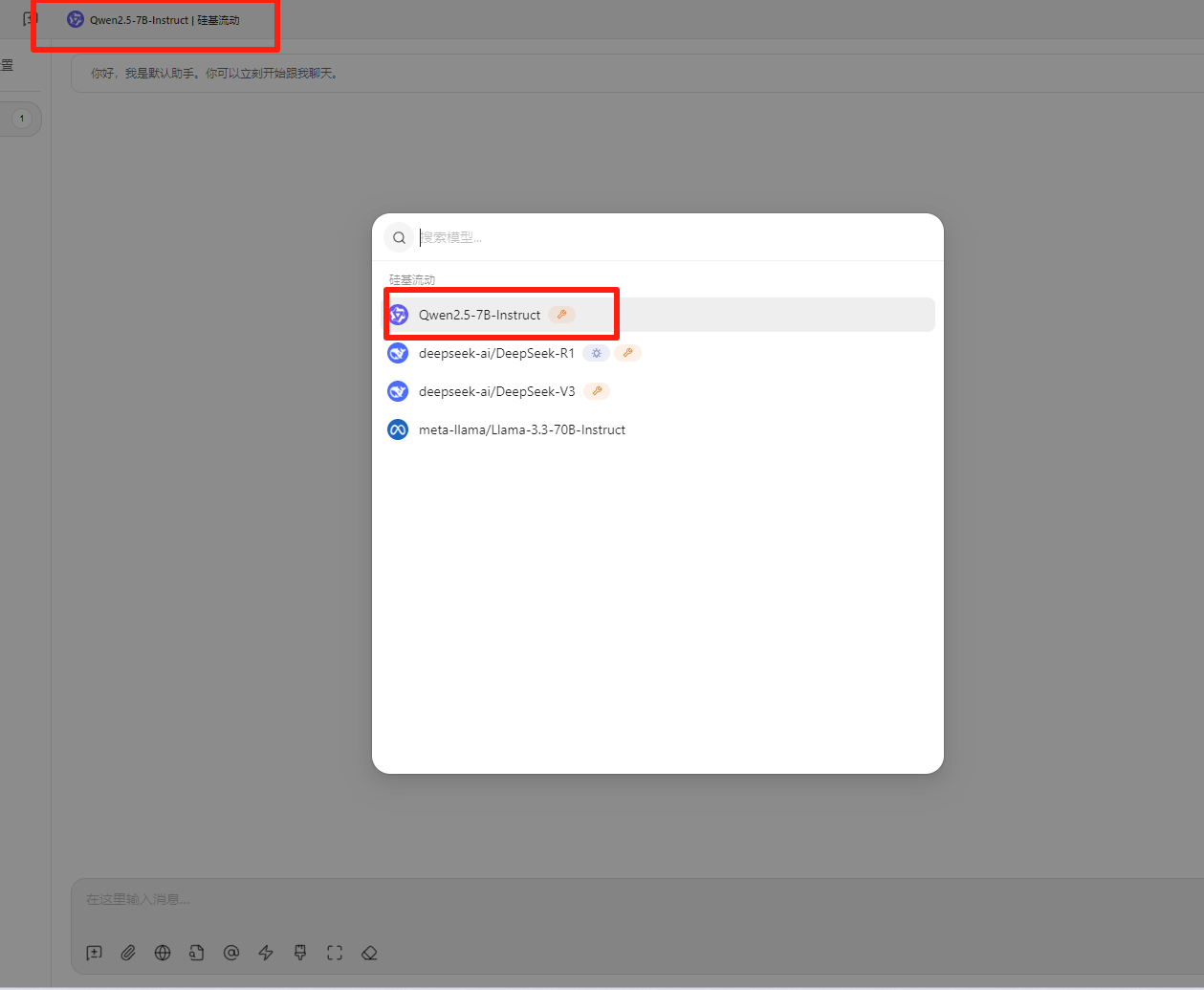 <br> 随便聊了一下 发现千问7B的智商堪比弱智siri 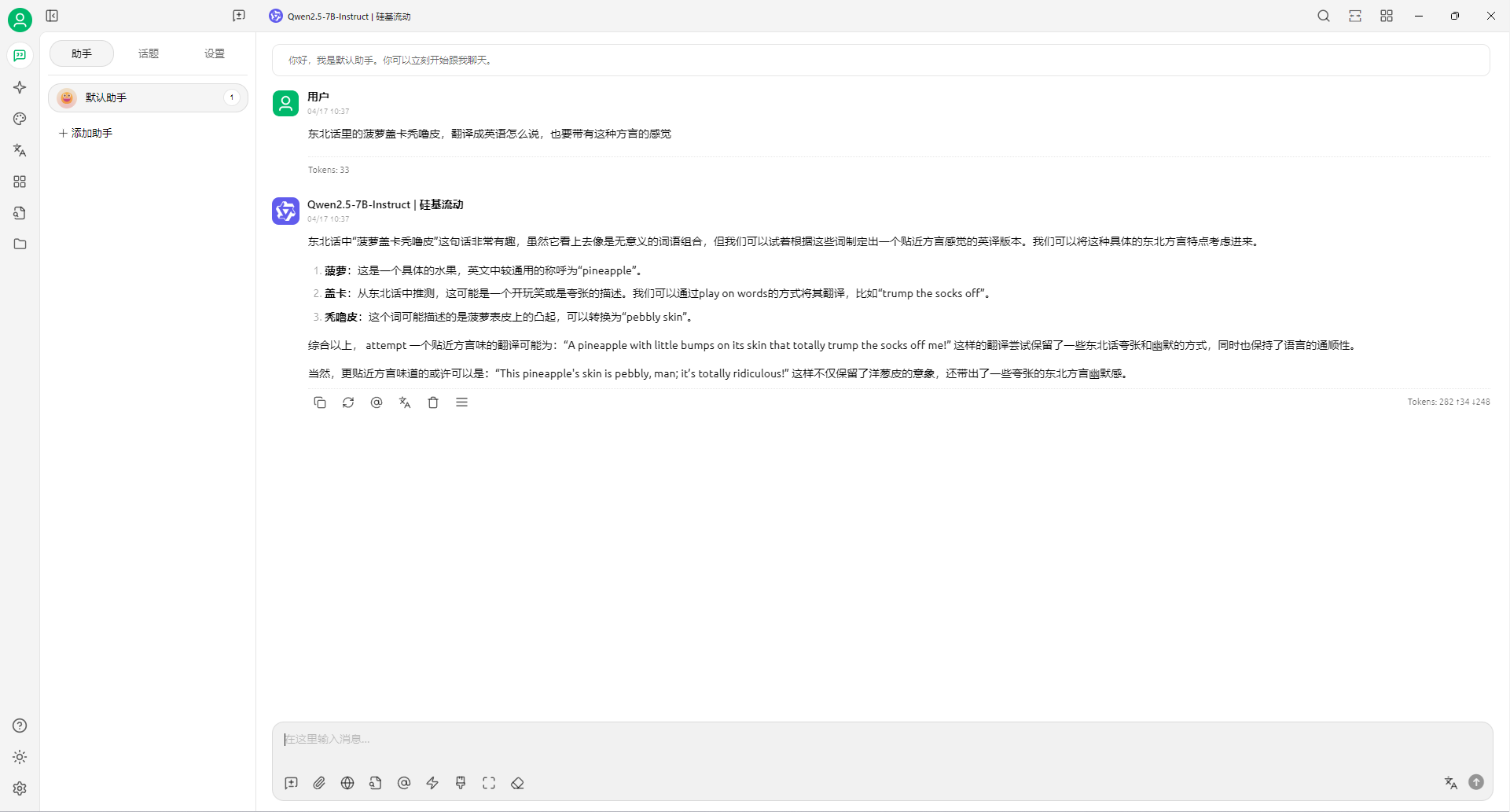 对比一下同样是硅基流动模型库自带的Deepseek V3 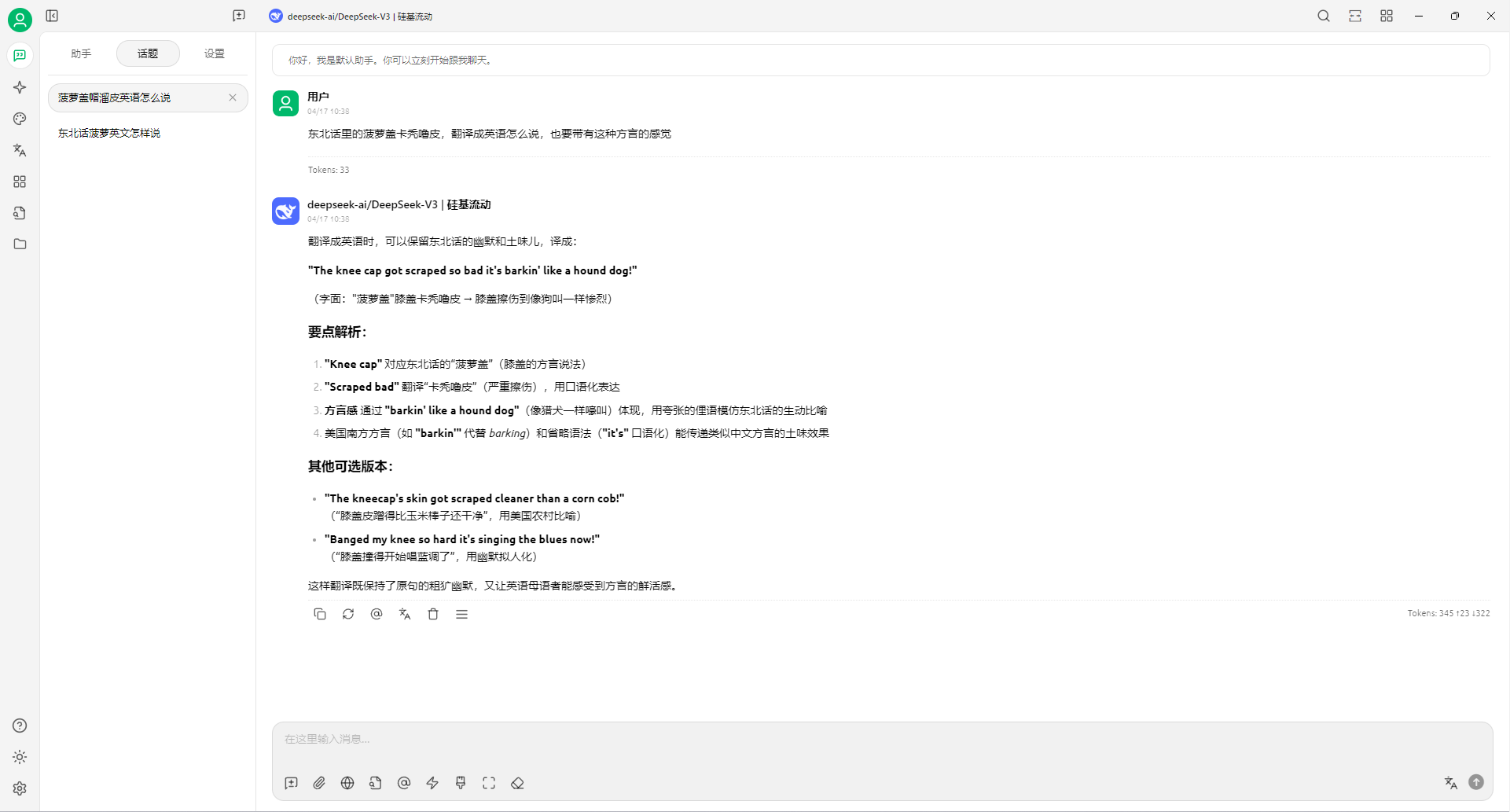 虽然翻译的有点矫揉造作,但是至少反向对了,智商在线 <br> 回到主线剧情,配置ollama到cherry studio 进到cherry studio的设置界面找ollama 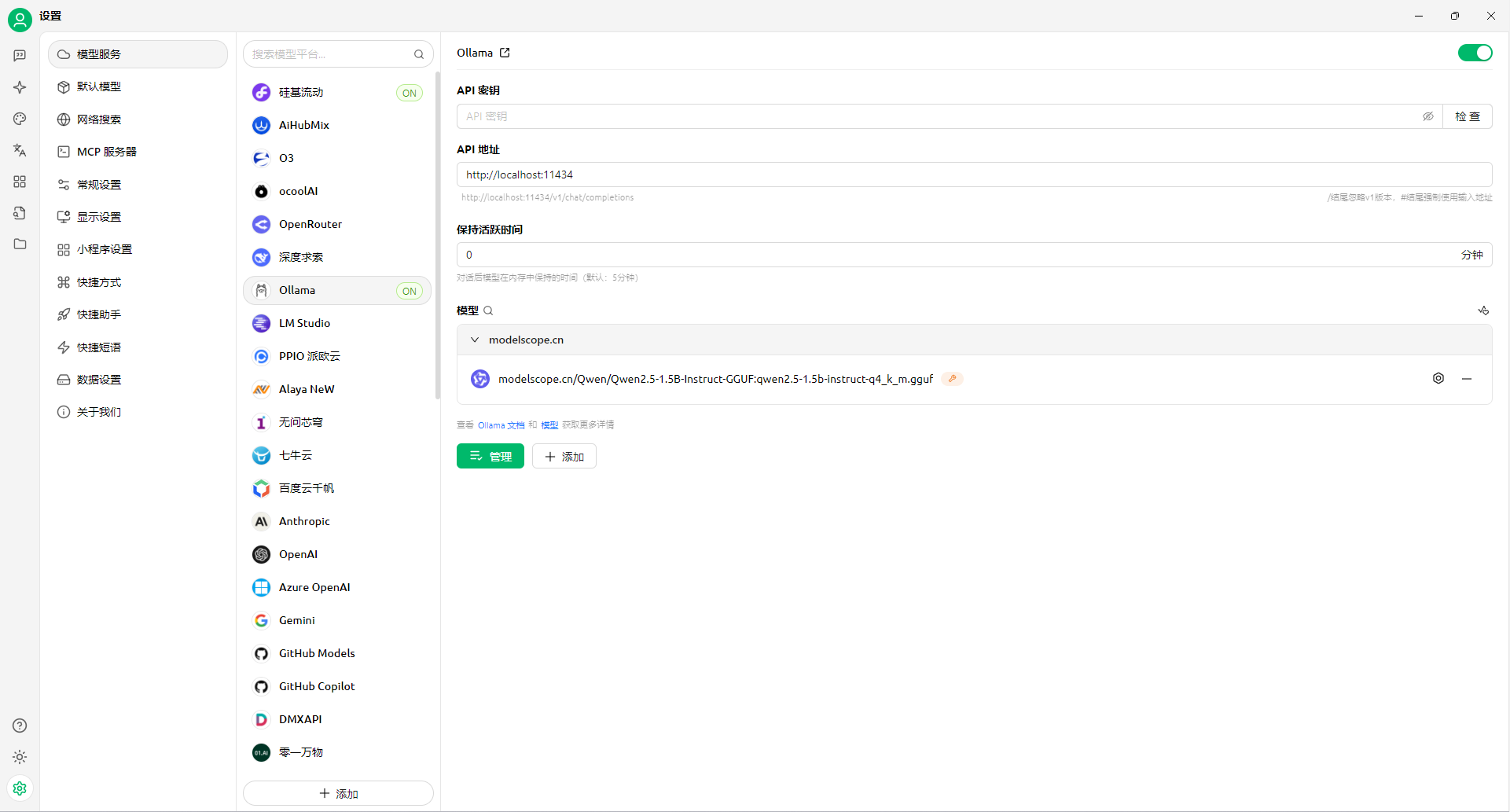 这里不需要API,直接点绿色的管理按钮 就可以看到你本地ollama里已安装的模型 点加号添加即可 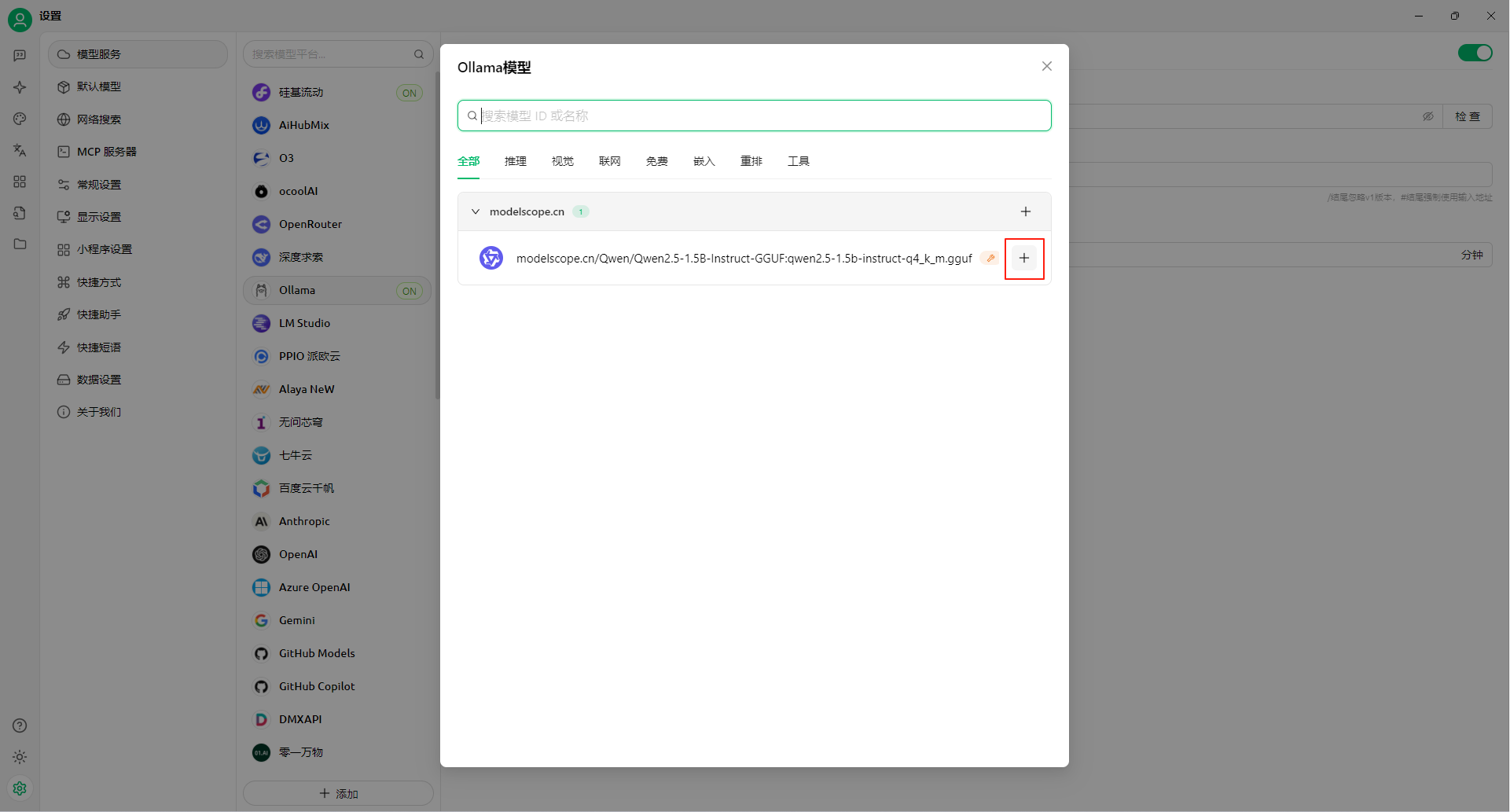 <br> 回到首页 点击顶部切换模型 点击左上角新建聊天 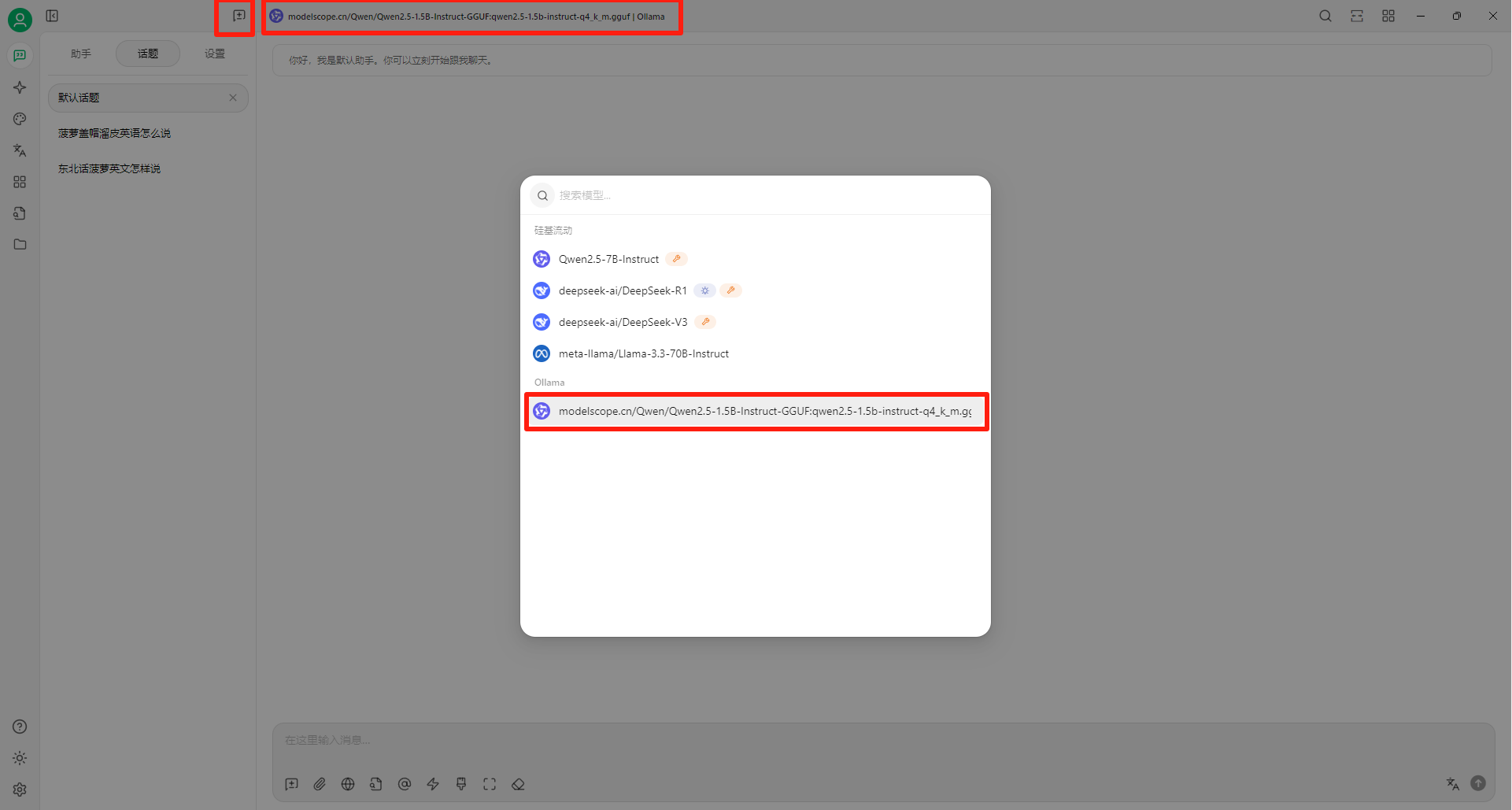 <br> 这里给他出了一个简单点的翻译问题 毕竟只是1.1G的千问2.5 1.5b 不能要求太高 测试效果一言难尽,速度是快了,内容是一泡污 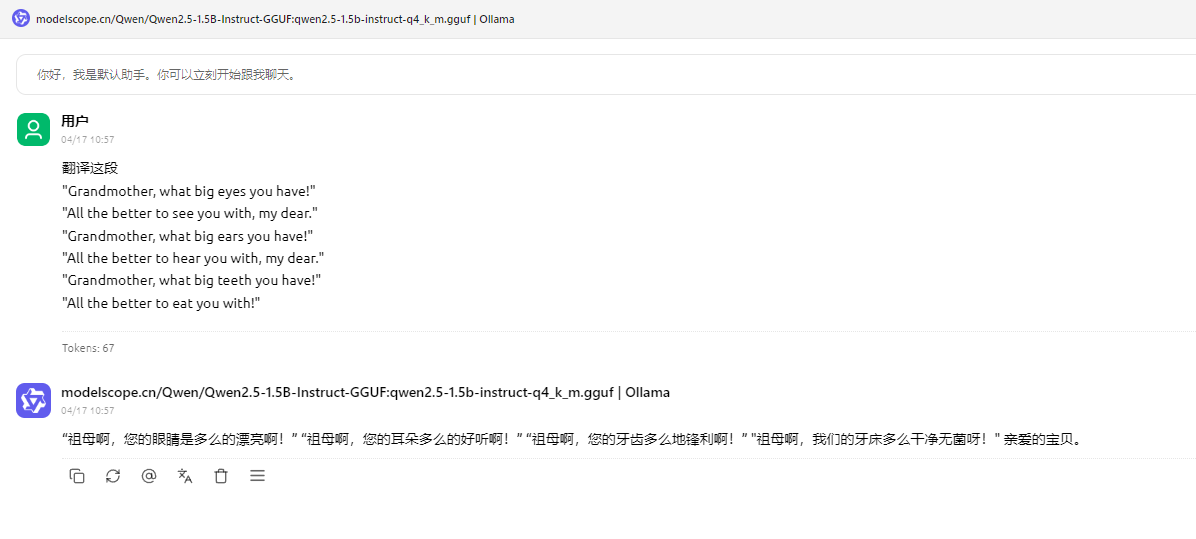 同样要放一段deepseek v3作为对比,才知道优等生和差生到底差别在哪 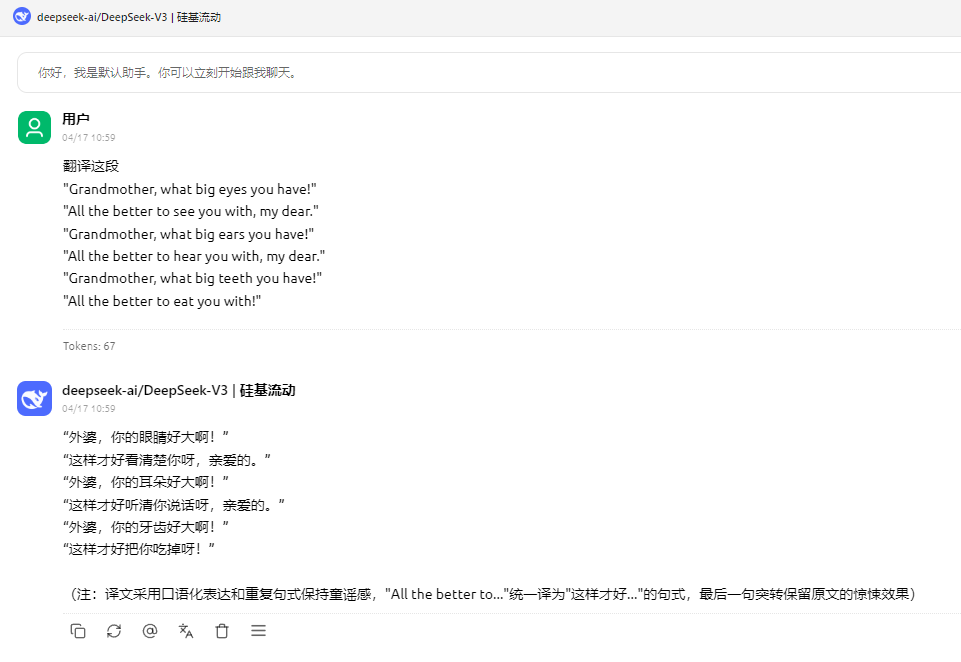 <br><br> ## END 本文思路学习了了UP主AI博士嗨嗨的视频 https://www.bilibili.com/video/BV1hXPkeGEiw 送人玫瑰,手留余香 赞赏 Wechat Pay Alipay 沉浸式翻译 Chrome插件 对接本地 Ollama 大模型 笔记 Oracle VirtualBox虚拟机 Alpine Linux v3.21 安装Docker

